2006-09-09
■ Development Environment Conference
開発環境カンファレンスで発表してきました。 聞いてくださったみなさん、ありがとうございました。
他の人達がすげーまっとうにツールとかの紹介をしてたのに対して、 わたしは old type バリバリのプレゼンをやってきました。
PowerPoint のファイルもあげときますが、 台本のほうが本文があって読みやすいと思うので、 そちらを以下にダラダラとつなげます。
■ DEC/1: イントロ
こんにちは、日本 Ruby の会の青木と言います。 今日は「オレポータビリティ」というテーマで 開発環境について話したいと思います。
自己紹介
まず簡単に自己紹介をしておきます。
自己紹介 (1) * 学生 * 専門は……哲学?
ふだんは大学生をやっております。 専門は強いて言うと哲学で、 プログラムは全然関係ありません。
ということは、
開発と言えば自宅
わたしにとって開発と言えば自宅でやるものです。
自己紹介 (2) * Ruby 関係者 * 標準添付ライブラリ メンテナ * 著書いろいろ
それから、普段は Ruby 方面で活動しています。 標準添付ライブラリをいくつか自分で書いて メンテしていますし、レポジトリのコミット権も持ってます。 その他にアプリケーション、ライブラリもいろいろと書きました。
それから本もいろいろ書きました。 具体的には、
著作 『ふつうのHaskellプログラミング』 『ふつうのLinuxプログラミング』 『Javaを独習する前に読む本』 『Rubyレシピブック』 『Rubyソースコード完全解説』 『Rubyを256倍使うための本 無道編』
ふつうのHaskellプログラミング や、 ふつうのLinuxプログラミング などです。
で、まあ、なにぶん Ruby 関係者ですので、
言語は ほぼ確実に RubyかC
プログラミングするときはほぼすべて Ruby か C です。
本当は Ruby だけいじって済ませたいんですが、 人が調子よくコマンドラインをたたいてるときに限って、
./lib/bitchannel/syntax.rb:398: [BUG] Segmentation Fault ruby 1.9.0 (2005-10-22) [x86_64-linux]
「……あれっ?」 なんてことが、起きるわけです。 こういうときはしょうがないので C プログラマになって ruby 本体をいじります。
■ DEC/2: 「開発環境」の定義
さて、今日は開発環境カンファレンスってことですが、 開発環境ってのもけっこう曖昧な言葉ですよね。 依頼されたときに何をしゃべろうか迷いました。
そこで、わたしはこの「環境」という単語を できるだけ広くとらえることにしました。
部屋
まず部屋。 これは当然開発環境でしょうね。
ハードウェア
それからハードウェア。
ソフトウェア
最後にソフトウェア。
この部屋、ハードウェア、ソフトウェアを 全部ひっくるめて開発環境と考えて、 この順番で話していきたいと思います。
■ DEC/3: 部屋の様子
そこで まず わたしの部屋から始めたいと思います。

こんな感じです。
わたしには 「ヒューマンインターフェイスには金をかける」 という信条があるので、 モニタと椅子だけは高いのを使ってます。
もっとも、そんなこと言いながらマウスは 1500 円です。
(あとで高林さん (だったかな) から質問があったので追記: 椅子はコンテッサ。ついでにモニタは EIZO FlexScan L665)
ちなみに後ろはこんな感じで、

本棚で埋めつくされてます。
で、またデスクトップに戻ります。

キーボードをよく見てもらうと、 これ、右側が切断されてます。

テンキーなんてぜんぜん使わないくせに 場所を食って邪魔だったので、 のこぎりで切り落としてしまいました。 こうするとナチュラルキーボードも コンパクトになって便利です。
■ DEC/4: ハードウェア
ところで、さきほどの写真では机の右側のほうを わざと写さなかったんですが、 ここに何があるかと言うと……

こういうものがあります。 これ全部コンピュータです。 写真に映っていないものも含めて すべて合わせると 20 台くらいあります。
しかもこれ、普通のパソコンばっかりじゃありません。 中には Alpha とか SPARC とか POWER が混じってます。 具体的には、
5 つのアーキテクチャ x86, AMD64, Alpha, SPARC, POWER
アーキテクチャ 5 つ
7 つの OS Linux, FreeBSD, NetBSD, Windows, Solaris, Tru64UNIX, AIX
オペレーティングシステムが 7 つ。 組み合わせだと、
9 つのプラットフォーム Linux/x86 Linux/AMD64 Linux/Alpha FreeBSD/Alpha NetBSD/Alpha Tru64UNIX/Alpha Solaris/SPARC AIX/POWER Windows/x86
9 つのプラットフォームがあります。
(注釈: 実は、 Development Environment Conference なので、DEC つながりで AlphaStation 500 の実物を持ってくる予定だった。 しかし出発の 30 分前に挫折)
「こんなに たくさんあって どうすんの?」
さて、マシンが 20 台くらいあるぜー、 と言うと、たいてい 「こんなにたくさんあって何に使うんだ」 と聞かれるんですけど、 主な役割は
愛でるため
愛でることです! なでて、
紺匡体 萌え〜
紺匡体萌えー と叫ぶためにあるんです。
まあ、そんなわけで、 マシンたちは なでるためにあるんですが、 せっかくマシンがたくさんあるわけですから、
ついでに Ruby のテストも している
ついでに Ruby のテストもしているわけです。
■ DEC/4: テーマ解説
ようやく今日のテーマにたどりつきました。
前提: マシン台数も プラットフォームも 多すぎる
わたしの開発環境は アーキテクチャも OS も多すぎます。 そのような状況だからこそ、
オレポータビリティ
今日のテーマである 「俺 - portability」の話になるのです。 この オレ ポータビリティ というのは、
俺 (の) portability
……の、ことです。 つまり、自分自身の portability のことです。 「ポータブルなプログラム」と言えば いろいろな環境において 動作するプログラムのことですね。 「俺がポータブルである」というのは、 いろいろな環境でも同じように開発できる、 ということです。
どんな環境でも 同じように開発できる → オレポータビリティが高い!
今日はオレポータビリティを高める 戦略について話そうと思います。
■ DEC/5: 戦略 (1) 必須ソフトウェアを限界まで削る
オレポータビリティを高める戦略、その 1 は、 どうしてもこれでなきゃだめ、 ないと死んじゃう、 というソフトウェアを減らすことです。
なぜかと言えば、
どこでも使える ソフトウェアが そもそも少ない
プラットフォームの種類が多い場合、 どこでも動くソフトウェアは限られます。 例えば IDE なんて絶望的です。
たくさんソフトウェアを 使うとインストールがめんどくさい
しかも、たくさんインストールしないといけないと インストールだけでバカみたいに手間がかかります。 パッケージシステムがどこにでもあるわけでは ないですから。
実例を見てみます。 例えばこれはメインマシンのデスクトップです。
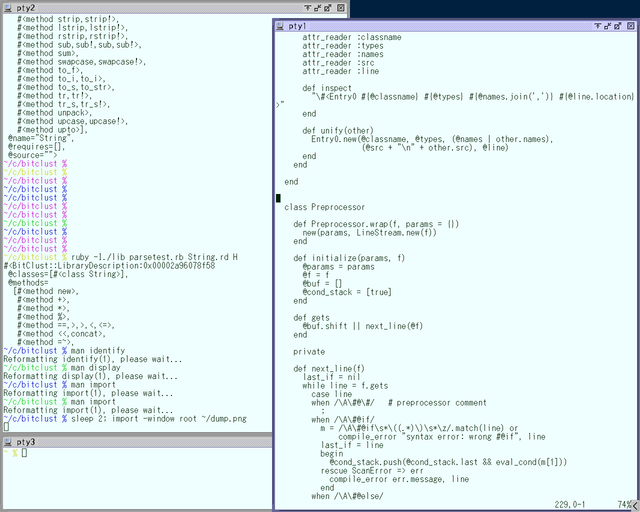
old type な人にありがちな、 味も素気もないデスクトップですね。 端末を 2 枚ひらいて、 右の端末でコード書いて、 左の端末でコマンドを打ちます。
このキャプチャに映ってる端末は rxvt なんですが、 別に rxvt でなければまずいわけではありません。 ちゃんと使えれば何でも使います。
ウィンドウマネージャは sawfish ですが、 これもやっぱりこだわってません。 単に Debian デフォルトだったから使ってるだけです。 だいたい何を使ってもそのうち慣れます。
画面は Linux ですが、別に Windows でもいいんです。 実際、このノートパソコンには Windows XP が入ってます。 Linux についても、 GNOME や KDE を使おうが使うまいがどっちでもいいんです。 どっちを使ってようと慣れれば大丈夫です。
で、端末やウィンドウマネージャは何でもいいとして、 必ずこれを使う、というものもあるわけです。 必ず使うのはこういうプログラムです。
必ず使うソフトウェア * Ruby * C コンパイラなど * zsh * CVS or Subversion * vi * 独自の開発ツール
順番に詳しく見ていきます。
使うプラグラム (1) Ruby 開発版 + 安定版ぜんぶ
まず当然 Ruby。 Ruby プログラムを書くのに Ruby がないと話になりません。
わたしは Ruby は開発版の最新を使うことに しているので、OS をインストールしたら まず CVS trunk HEAD を自分でコンパイルします。
さらに、安定版をねこそぎ入れます。 いまは 1.8 系列が安定版なので、 1.8.0 から 1.8.5 まで全部入れるわけです。 これは動作の検証用です。
ただ、たくさんあると各バージョンで 比較するのも面倒なので、
forall-rubyコマンド 横断テストの自動化
forall-ruby コマンドという自作コマンドを使います。 このコマンドは、システムにあるすべての ruby に 対して同じオプションをつけて実行するコマンドです。
例えば次のコマンドを実行すると、
~ % forall-ruby -e 'p Object.superclass' aamine@core ruby 1.8.2 (2004-12-25) [i386-cygwin] nil ruby 1.8.3 (2005-09-21) [i386-cygwin] nil ruby 1.8.4 (2005-12-24) [i386-cygwin] nil ruby 1.8.5 (2006-08-25) [i386-cygwin] nil ruby 1.9.0 (2006-08-23) [i386-cygwin] BasicObject
ああ Ruby 1.9 では Object の上に BasicObject てのが 追加されたんだなあとわかります。
使うもの (2) C コンパイラなど gcc, bison, flex, autoconf, make, ...
次に C コンパイラとか autoconf。 こいつらは Ruby をコンパイルするのに 必要なので否応なく入れます。
使うもの (3) zsh
それから zsh です。実は zsh は インストールするのが結構大変なんですが、 もう bash では生きていけない身体に なってしまったので やむなく使います。
使うもの (4) vi
それから vi。 UNIX 系の OS ならフツー入ってるので楽です。 Windows でも Cygwin を入れればついてきますし。
また、これは vim とかではなく vi であるところも重要です。 わたしはシンタックスハイライティングだとか オートコンプリートだのは 一切使わないことにしているので、 素の vi で大丈夫です。
ちなみに、素の vi はマルチバッファではないので 複数ファイルが編集できません。 そこで、複数ファイルをいじるときは シェルのジョブ制御機能を使います。
複数ファイルを編集するときは シェルのジョブ制御を使う Ctrl-z でサスペンド、 fg コマンドで復帰
もはやジョブ制御なんて知らない人もいそうですが、 こういう機能もあるんです。
使うもの (5) バージョン管理システム (CVS か Subversion)
それからバージョン管理システム。 種類はなんでもいいんですが、 わたしは CVS をメインに使ってます。
※ 追記: id:naoya さんの発表によれば CVS を使っていいのは小学生までらしい。
使うもの (6) 独自の開発ツール * ReFe * rdefs
その他、いくつか自作のツールがあります。 Ruby に特化していますが、 アイデア自体は他の言語でも変わらないでしょう。
具体的に見ますと、
ReFe Rubyのリファレンスマニュアルを 検索するツール
まず ReFe というツールです。 これは Ruby のリファレンスマニュアルを検索するツールです。
例えば String クラスの each_with_index メソッドを調べたい! というときには
~ % refe string each_with_index aamine@core
String < Enumerable#each_with_index
--- each_with_index {|item,index| ... }
要素とインデックスを両方与えるイテレータ。
self を返します。
と指定すればいいわけです。
ちなみに、この場合は each_with_index メソッドは Enumerable モジュールから継承したメソッドなんですが、 そういうメソッドもちゃんと検索できます。
rdefsコマンド 定義されてるクラスとメソッドをリスト
それから rdefs コマンド。 これは、ファイルに定義されてる クラスとかメソッドをリストするコマンドです。
例えばこの locale.rb というファイルに どんなメソッドが定義されてるかなーと思ったら、
~ % rdefs locale.rb
module BitChannel
class Locale
def Locale.declare_locale(key, loc)
def Locale.get(key)
def Locale.key?(key)
def Locale.keys
def initialize
def rc_table
private :rc_table
def [](key)
alias text []
def []=(key, str)
def inspect
と、いうふうに調べればいいわけです。
独自ツールのポイント * Ruby だけを使って書く * インストーラを付ける
まずツールはポータビリティを考えて すべて pure Ruby で書きます。 例えば、なぜかツールを Python で書いちゃったりしたら また Python 入れなきゃいけませんから、 とうぜんここは Ruby を使うわけです。
それからインストーラを付けること。 マシンが 20 台あるってことは、 OS のインストールも最低 20 回やるわけです。 それだけあると、ツールにもインストーラが ついていたほうが楽です。
■ DEC/6: 戦略 (2) カスタマイズしない
オレポータビリティを高める戦略の 2 つめは、 ソフトウェアをカスタマイズしないことです。
なにしろマシンが 20 台からあるので、
いちいち カスタマイズ してられるか!
いちいちカスタマイズするのも面倒です。 じゃあ設定を共有するか、とか言い出すと、 今度はそっちのインフラ整備が面倒です。
ということで、ソフトウェアを細かく カスタマイズするのをあきらめます。
これも、本当にまったく カスタマイズしないわけではなくて、 「できるだけ」カスタマイズしないということです。 さすがにわたしも zsh はちょっといじりたいですし。
これを逆に言うと、
カスタマイズしなくても 使う気になるソフトだけ使う!
カスタマイズしなくても使う気になる ソフトウェアだけ使うということです。 「〜〜をインストールして設定すれば使える」 なんてのは使えないのと同じだと思いましょう。
英語で言うと、
No configuration is good configuration.
No configuration is good configuration です。 設定しないで使えるのが一番いいってことですね。
さらに日本語で言い直すなら、
ノウハウを作らないのがノウハウ
ノウハウを作らないのがノウハウです。
■ DEC/7: 戦略 (3) ホームディレクトリ構造の共通化
オレポータビリティを高める戦略の 3 つめは、 すべてのマシンでホームディレクトリの構造を統一することです。 これはまあ、あたりまえと言えばあたりまえでしょう。
各種設定を減らすためにも 共通化が重要
ホームディレクトリの構造が同じなら、 その構造を前提にしてツールが書けます。 そうすると設定が減って楽になると。
また英語で言うと、
Convention over configuration.
Convention over configuration、ということです。 日本語で言うなら「慣習じゅーよー」。
具体的にどういう構造にするかはいろいろあると思いますが、 わたしは UNIX の /usr 以下と同じ構造にしています。
UNIX の /usr 以下を真似 bin, etc, lib, share, src, var
ちなみに、src はもちろんソースコードですが、 ここには自分が作ったもの以外をまとめます。 で、
自分で作ったものは ~/c に置く
自分で作ったものは すべて ~/c に置きます。 ソースコードもツールも、すべてです。
■ DEC/8: 戦略 (4) バージョン管理
オレポータビリティを高める戦略その 4 は、 徹底的にバージョン管理システムを使うことです。
共有するため
バージョン管理システムを使う目的は、 この場合、マシン間でファイルを共有することです。
~/c 以下は例外なく バージョン管理システムに入れる
~/c 以下、つまり自分で作ったものは すべてバージョン管理システムで管理します。 具体的には、
ソースコード
プログラムのソースコードやドキュメント。
開発ツール
さっき言ったような、独自の開発ツール。
大学のレポート
それに大学のレポートもですね。
とにかく自分が作ったものはすべてここに入れて、 バージョン管理システムで管理します。
ちなみに C は working Copy の C から取りました。
■ DEC/9: まとめ
では、まとめます。 オレポータビリティを高めるための 戦略は 4 つありました。
戦略 (1) 必須ソフトウェアを限界まで削る
一つめは、「これがないと死んじゃう」 ソフトウェアを限界まで減らすことです。 これによってインストールする手間を 減らすと同時に、ポータビリティを高めます。
戦略 (2) カスタマイズしない
二つめは、ソフトウェアのカスタマイズを 半ばあきらめることです。 デフォルト設定が優秀なソフトだけ使いましょう。 No configuration is good configuration.
戦略 (3) ホームディレクトリの共通化
三つめはホームディレクトリの構造を 共通化することです。 Convention over configuration.
戦略 (4) 徹底的にバージョン管理
四つめは、バージョン管理システムを 徹底的に使うことです。 バージョン管理システムを使うことで ファイルの共有も実現できます。
結論: あたりまえのことを 徹底的にやるのが ポイント
今日の話は、どれも けっこう あたりまえのことが多かったと思います。 バージョン管理するというのも、 ホームディレクトリを同じにするというのも、 まあ普通ですよね。 でも、それを徹底活用すると、 マシンが 20 台あっても OS が 7 種類あっても 生きていけるようになるわけです。 これが今日のポイントです。
以上でわたしの発表は終わりです。 ご静聴ありがとうございました。
(16:45)
■ ひら [キーボードがSK6000だ!使ってました(^-^)
10年くらい前の名作キーボードだね。]
■ 青木 [え、このキーボードって有名なんですか。
ロゴも入ってないし、確か 7000 円くらいで、
ナチュラルキーボードのくせに安いなあ〜
っていう印象しかなかったです……。
秋葉原の俺コンスポットで買った記憶があります。
タッチパッドのついてるのとついてないのがあった。]